Debezium vs DBConvert Streams: Which Offers Superior Performance in Data Streaming?

In contemporary application design that utilizes microservices and keeps up with dynamic analytics demands, it's common to synchronize data from various databases dispersed throughout an enterprise and integrated with diverse systems. In modern applications, real-time syncing of databases is often necessary, so the synchronization cannot wait for a batch job to run daily or even hourly.
The Change Data Capture concept addresses this need for real-time syncing by capturing and tracking any changes made to the data in the source databases and propagating those changes to the target databases in real time.
As organizations continue to generate and store large amounts of data, the need for efficient and reliable real-time data replication has become increasingly important. Two solutions in this space are Debezium and DBConvert Streams.
Both platforms promise to replicate data between different types of databases, but which one is right for you? In this article, we'll compare DBConvert Streams and Debezium in terms of performance.
Debezium/ Kafka architecture
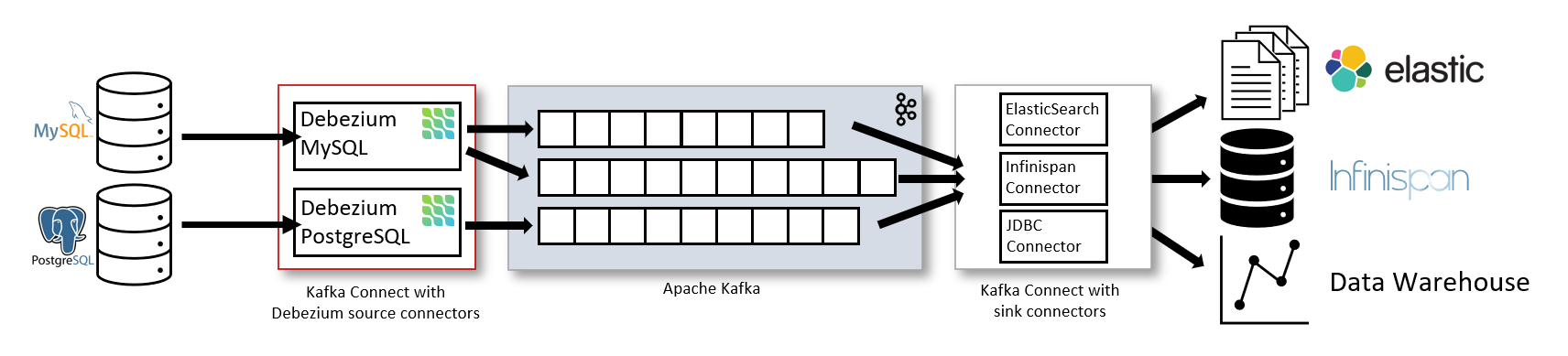
The architecture for Change Data Capture using Debezium and Kafka Connect involves several components working together to capture, process, and route the data changes.
- Source Database: The source database is where the changes occur, emitting events on inserts, updates, and deletes.
- Debezium Connector: Debezium provides connectors for different databases, which capture the changes in a database-agnostic way and convert them into a standard message format.
- Apache Kafka: Kafka is a distributed streaming platform that acts as a message queue and ensures that the messages are delivered in order and without loss.
- Kafka Connect: Kafka Connect is a component of Kafka that handles the integration between Kafka and external systems. It is used to pull data from Debezium and push it to the destination systems.
- Consumer Applications: These applications consume the captured data changes and process them according to the use case. They could be analytics applications, data warehouses, or any other application that requires real-time data.
DBConvert Streams architecture.
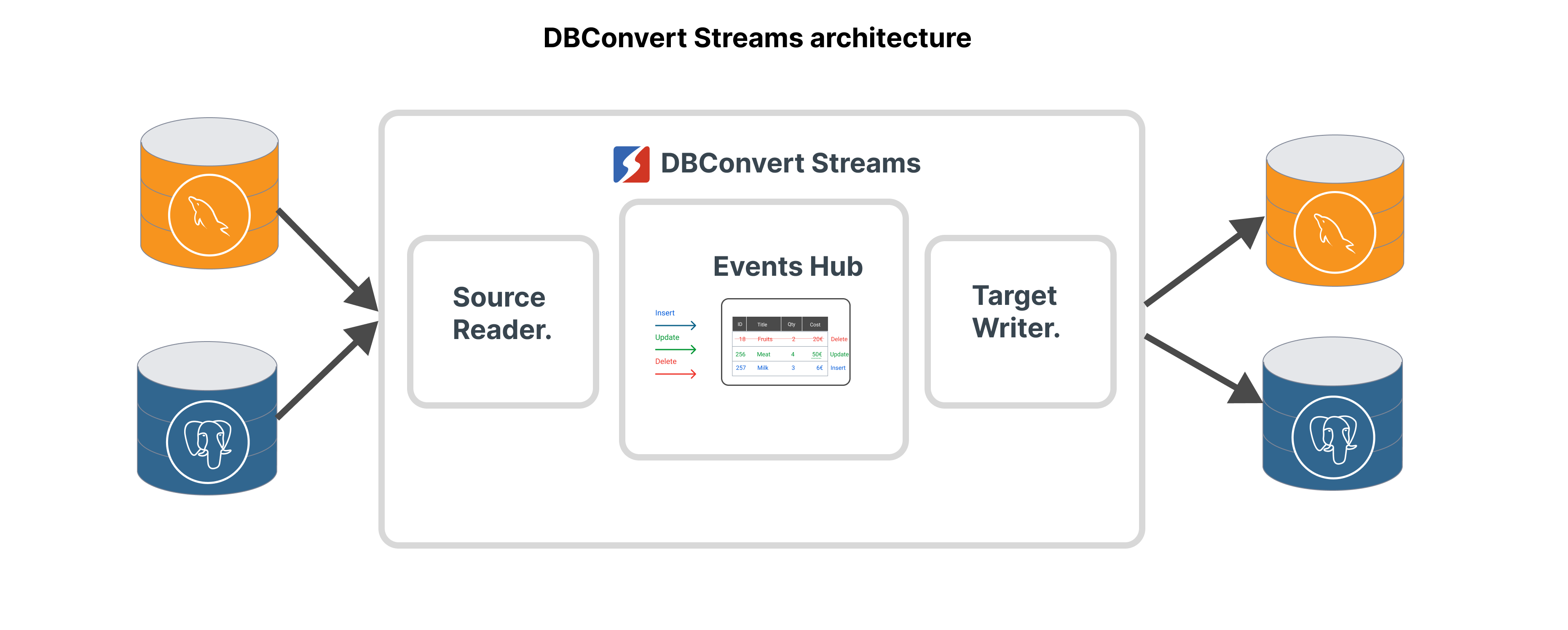
In the DBConvert Streams architecture, the flow of data is as follows:
- The DBConvert Streams database source reader component reads CDC changes from the upstream source database.
- The source reader component propagates the changes to the NATS message broker. DBConvert Streams (DBS) uses NATS instead of Kafka in its architecture for Change Data Capture. The NATS message broker acts as a message queue, ensuring reliable and efficient delivery.
- The DBS target writer component consumes the events from the NATS message broker and writes them to the target database.
This architecture enables real-time data integration between different databases, making it easier for development teams to work with diverse databases and reducing the amount of custom code needed to implement CDC.
Different Database Log formats.
There is no common standard for the format of database logs. Each database system typically uses its proprietary format for its transaction logs. This lack of standardization can make it challenging for developers to work with change data capture, particularly in multi-database environments.
To address this issue, Debezium, and DBConvert Streams offer connectors for popular databases, thereby simplifying the implementation of CDC.
Performance tests.
We will set up the test environment using Docker Compose to start all services and conduct performance tests to compare the efficiency of Debezium and DBConvert Streams in replicating one million records from a MySQL source database to a Postgres target database.
We have created a GitHub repository to store the test scripts and results:
Prerequisites.
Before proceeding, please ensure you have installed the necessary prerequisites, including Docker, Docker compose, and curl.
Please clone the specified repository onto your local machine.
git clone git@github.com:slotix/dbconvert-streams-public.gitTable structure.
+---------+---------------+------+-----+-------------------+
| Field | Type | Null | Key | Default |
+---------+---------------+------+-----+-------------------+
| id | bigint | NO | PRI | NULL |
| name | varchar(255) | NO | | NULL |
| price | decimal(10,2) | NO | | NULL |
| weight | double | YES | | NULL |
| created | timestamp | YES | | CURRENT_TIMESTAMP |
+---------+---------------+------+-----+-------------------+Source and Target Databases.
mysql-source database image is based on slotix/dbs-mysql:8, which has all the necessary settings to enable MySQL CDC replication. This image also contains the initdb.sql script, which creates a table with the above structure.
postgres-target database is based on the official postgres:15-alpine image. It will receive all changes made to the mysql-source database.
These databases are typically hosted on separate physical servers in a production environment. However, we will run them on a single machine using separate containers for our example.
Debezium test.
cd dbconvert-streams-public/examples/mysql2postgres/1-
million-records-debezium
export DEBEZIUM_VERSION=2.0
docker-compose up --build -dSet the environment variable DEBEZIUM_VERSION to 2.0 and then run the docker-compose up command with the options --build to build the images and -d to start the containers in the background.
Deployment
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @source.json
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @target.jsonThese two curl commands create Kafka Connect connectors for Debezium to read data from the MySQL source database and write data to the Postgres target database.
Visit http://localhost:8083/connectors/ to view a list of active and running connectors.
Monitor the number of records on the target.
To ensure that the replication process is working correctly, we will monitor the number of records on the target database using the script below.
#!/bin/bash
count=0
start_time=0
while true; do
output=$(docker compose exec postgres-target bash -c "psql -U \$POSTGRES_USER \$POSTGRES_DB -c 'select count(*) from products'")
count=$(echo "$output" | sed -n '3p' | awk '{print $1}')
if [[ $count -gt 1 && $start_time -eq 0 ]]; then
start_time=$(date +%s)
echo "Started at"
fi
if [[ $count -gt 1000000 ]]; then
end_time=$(date +%s)
elapsed_time=$((end_time - start_time))
echo "Record count exceeded 1000000 after $elapsed_time seconds."
break
fi
echo "$output" | sed -n '3p' | awk '{print $1}'
sleep 1
doneThe script will print the number of records in the target database every second. Once the number of records exceeds 1 million, the script will print the elapsed time and exit.
In the next terminal run the following commands:
export DEBEZIUM_VERSION=2.0
./count.sh
Populate the source table with sample data.
To execute the SQL script that populates the source table with sample data, you can run the following commands in the first terminal:
docker compose exec -it \
mysql-source \
mysql -u root -p123456 -D source
In MySQL prompt, execute the following command:
INSERT INTO products (name, price, weight)
SELECT
CONCAT('Product', number) AS name,
ROUND(RAND() * 100, 2) AS price,
RAND() * 10 AS weight
FROM
(SELECT @row := @row + 1 AS number FROM
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t1,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t2,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t3,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t4,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t5,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t6,
(SELECT @row := 0) r
) numbers
LIMIT 1000000;products.Results.
Once the operation is completed, you can see something like this in the terminal where the count.sh script is running.
....
942882
960702
977532
995352
Record count exceeded 1000000 after 96 seconds.That means it took about 96 seconds to replicate 1 million records from MySQL to Postgres Database.
DBConvert Streams test.
We are going to make the same test with DBConvert Streams.
cd dbconvert-streams-public/examples/mysql2postgres/1-
million-records
docker-compose up --build -dThe command above will start the services in the background, build the images and use the docker-compose.yml file to configure the services.
Send stream configuration.
Send a request to the DBConvert Streams API with configuration parameters.
Run the curl command :
curl --request POST --url http://127.0.0.1:8020/api/v1/streams\?file=./mysql2pg.jsonPopulate the source table with sample data.
Connect to the MySQL container to interact with the MySQL database running inside the container.
docker exec -it \
mysql-source \
mysql -uroot -p123456 -D sourceIn MySQL prompt, execute the following command
INSERT INTO products (name, price, weight)
SELECT
CONCAT('Product', number) AS name,
ROUND(RAND() * 100, 2) AS price,
RAND() * 10 AS weight
FROM
(SELECT @row := @row + 1 AS number FROM
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t1,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t2,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t3,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t4,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t5,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t6,
(SELECT @row := 0) r
) numbers
LIMIT 1000000;products.Results.
Copy and paste the URL into your web browser to access the Prometheus metrics page.
http://127.0.0.1:9090/graph?g0.expr=source_events_in&g0.tab=1&g0.stacked=0&g0.show_exemplars=0&g0.range_input=1h&g1.expr=source_duration_seconds&g1.tab=1&g1.stacked=0&g1.show_exemplars=0&g1.range_input=1h&g2.expr=target_events_out&g2.tab=1&g2.stacked=0&g2.show_exemplars=0&g2.range_input=1h&g3.expr=target_duration_seconds&g3.tab=1&g3.stacked=0&g3.show_exemplars=0&g3.range_input=1hOnce you're on the page, you'll be able to see various performance metrics related to the replication process, including the number of events in and out of the source and target databases and the duration of the replication process.
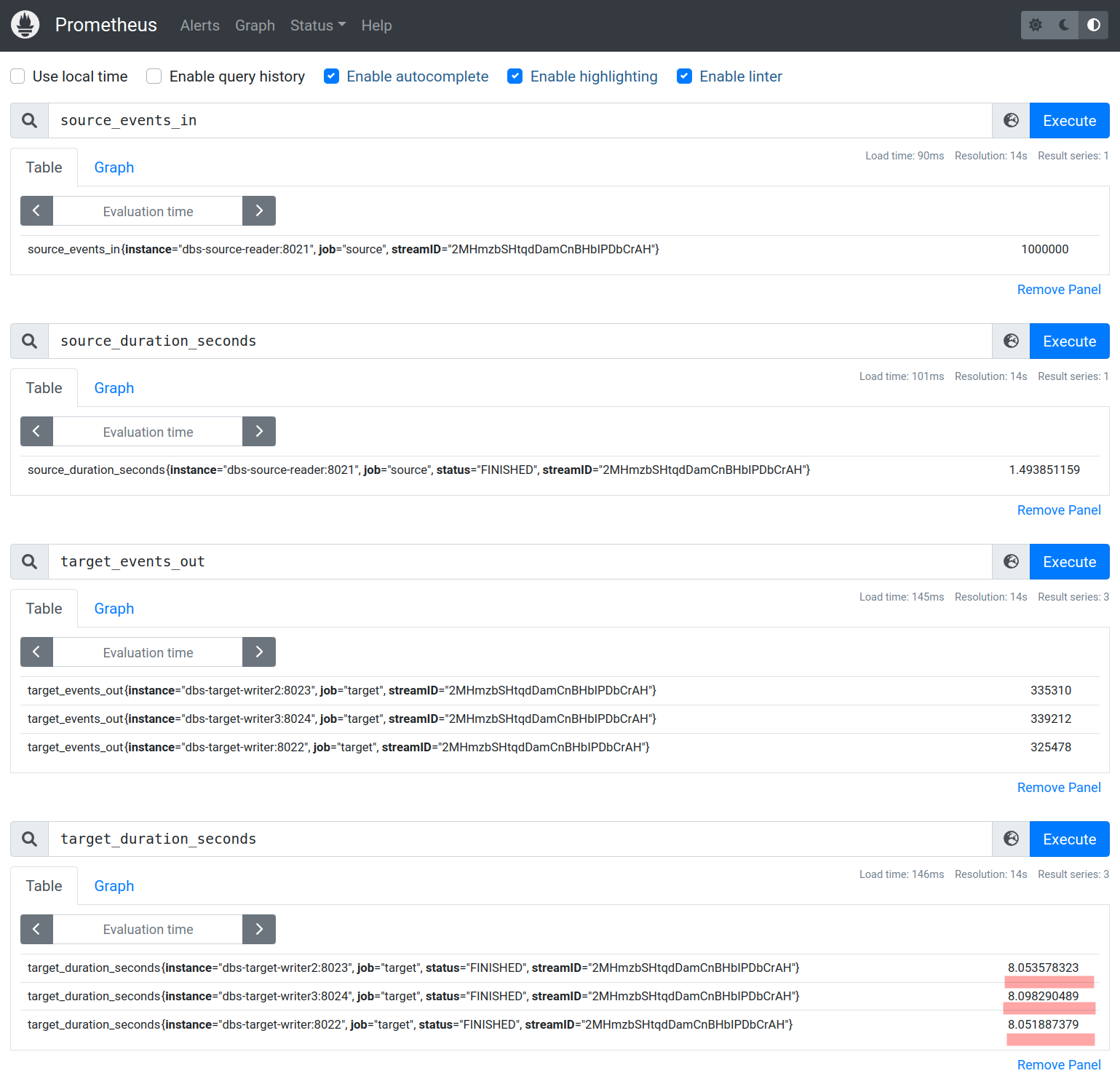
It took about 8 seconds to transfer million records from MySQL to Postgres.
Minimum hardware requirements.
We conducted additional tests as described above on the DigitalOcean cloud computing platform to find out the information about the minimum hardware resources Debezium and DBConvert Streams requires. The table below summarizes the test results.
The table below summarizes the test results of replication of 1 Million records from MySQL to PostgreSQL.
| Hardware Resources | Debezium | DBConvert Streams |
|---|---|---|
| 2 CPU / 2 GB RAM | Failed | 15 seconds |
| 2 CPU / 4 GB RAM | Failed (after ~300k records) | 12 seconds |
| 4 CPU / 8 GB RAM | 236 seconds | 8 seconds |
| 8 CPU / 16 GB RAM | 221 seconds | 8 seconds |
According to the table, the DBConvert Streams platform requires fewer resources and provides faster replication speeds compared to Debezium.
Conclusion
While Debezium is a popular CDC platform that offers a lot of flexibility and powerful features, it may not always be the most cost-effective solution for some use cases.
Specifically, DBConvert Streams may provide better performance and cost-efficiency for use cases requiring high throughput and real-time replication.