Change Data Capture (CDC): What it is and How it Works?
Change Data Capture (CDC) captures incremental changes in the original database so that they can be propagated to other databases or applications in near real-time.
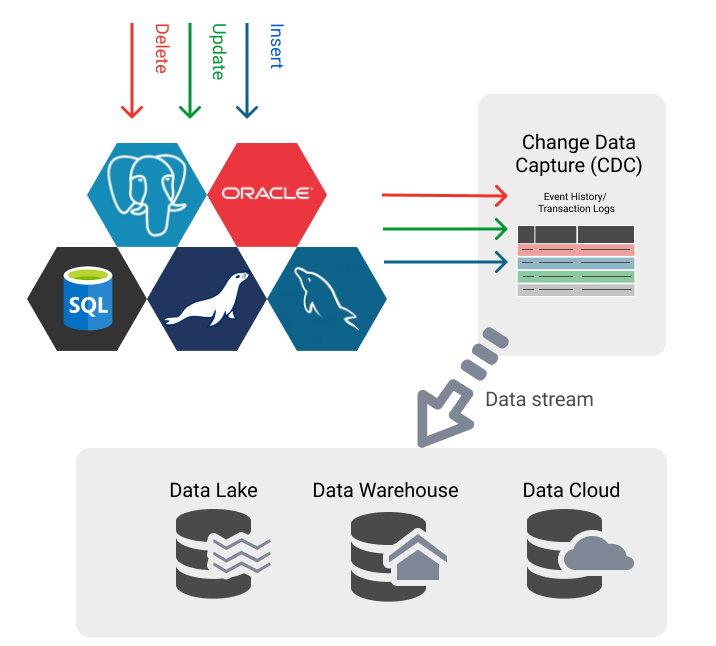
Change Data Capture (CDC) has become the ideal solution for low-latency, reliable, and scalable data replication between relational databases, cloud databases, or data warehouses in high-velocity data environments. In this article, we will introduce four different Change Data Capture (CDC) methods.
Traditionally, companies have used batch (bulk) data loading to periodically migrate data from a database to another database or data warehouse several times a day. Batch loading and periodic reloading with the latest data take time and often consume significant processing power on the original system. This means that administrators need to run replication workloads during the times when production is suspended or will not be heavily affected. Batch transfers are becoming increasingly unacceptable in today's global 24x7 business environment.
What is Change Data Capture?
Change Data Capture (CDC) captures incremental changes to data and data structures (also called schemas) from the source database. So that changes can be propagated to other databases or applications in real time or near real time. In this way, CDC provides efficient low-latency data transfers to data warehouses, where the information is then transformed and delivered to analytics applications.
Replication of time-sensitive information is also an important aspect when migrating to the cloud when data is constantly changing, and it is impossible to interrupt connections to online databases.
Change Data Capture has three fundamental advantages over batch replication:
- CDC reduces the cost of transferring data over the network by sending only incremental changes.
- CDC helps you make faster, more accurate decisions based on the most recent, up-to-date data. For example, CDC propagates transactions directly to analytics applications.
- CDC minimizes disruption to production workloads.
Ten Benefits of change data capture.
- Real-time or near real-time capture of individual data changes.
- Faster data propagation and synchronization between systems.
- Up-to-date destination database with the latest changes.
- Reduced impact on system performance by capturing only changed data.
- Decreased network traffic and resource utilization.
- Granular and detailed information about data changes.
- Timestamps and transactional context for data auditability.
- Enhanced compliance, auditing, and tracking capabilities.
- Improved efficiency in data synchronization workflows.
- Enhanced data accuracy and real-time data integration.
Change Data Capture Methods
There are several Change Data Capture methods to track and deliver changed data, and which one you choose depends on the requirements of your application and the tolerance for performance degradation. Here are the general techniques, how they work, as well as their advantages and drawbacks.
"Timestamps or version numbers" tracking.
Tables that need to be tracked can have a column representing the last modified timestamp or version number.
Database designers usually name such columns as LAST_UPDATE, DATE_MODIFIED, VERSION_NUMBER, etc.
Any row in the table that is timestamped after the time of the last data capture is considered modified. Or, for a version-based tracking method, all data with the latest version number is deemed to be modified when a change occurs.
Combining versions and timestamps to track data in database tables allows you to use logic such as "Capture all data for version 3.4 that changed since June 22, 2021."
Pros:
- Simple
- It can be built using your own application logic.
- It doesn't require any external tools.
Cons:
- Adds additional overhead to the database.
- This approach requires CPU resources to scan tables for modified data and maintenance resources to ensure that the LAST_UPDATE column is reliably applied to all source tables.
- There is no LAST_UPDATE for a deleted row. DML statements such as "DELETE" will not propagate to the target systems without additional scripts to track the deletions.
- It is error-prone and can cause data consistency issues.
Table differencing / Deltas.
Another change data capture approach uses utilities such as table delta or 'tablediff' to compare data in two tables for mismatched rows. Then you can use additional scripts to apply the differences from the source table to the target table.
While this works better than "Timestamps" CDC for managing deleted rows, there are still several problems with this approach. CPU resource consumption required to distinguish differences is significant, and the overhead increases linearly as the number of data increases.
Analytic queries against the source databases or production environment can also degrade application performance. For these reasons, you can periodically export your database to a staging environment for comparison. The problem is that shipping costs grow exponentially as data volumes increase.
Another problem with diffs is the inability to capture intermediate changes to your data. Let's say someone updates a field but then changes it back to its original value. If you run a simple comparison, you will not be able to capture these change events. The diff method introduces latency and cannot be executed in real-time.
Pros:
- It provides an accurate view of changed data while only using native SQL scripts
Cons:
- Storage demand increases because you need three copies of the data sources used in this method: original data, previous snapshot, and current snapshot.
- It does not scale well in applications with heavy transactional workloads.
"Table differencing" and "Timestamps" CDC methods are not suitable for production environments.
For large datasets, it is advisable to use the following two Change Data Capture methods. However, the "trigger-based" and "transaction log" change data tracking methods serve the same purpose in different ways.
Trigger-based CDC

"Trigger-based CDC" or "Event Sourcing" is one method for building change data capture for large databases.
- For each database table participating in replication, three triggers are created that are triggered when a specific event occurs in a record:
- INSERT trigger that fires when a new record is inserted into the table.
- UPDATE trigger that fires when a record is changed;
- DELETE trigger that fires when a record is deleted.
- The shadow table "Events History" is stored in the database itself and consists of the sequence of state-changing events.
- Whenever an object's state changes, a new event is appended to the sequence. The information about the changed record goes to the "Events History" shadow table.
- Then, based on the events in the History table, the changes are propagated to the target system.
A simple "History" table might look like this:
| Id | TableName | RowID | TimeStamp | Operation |
|---- |----------- |------- |-------------------- |----------- |
| 1 | Customers | 18 | 11/02/2021 12:15am | Update |
| 2 | Customers | 15 | 11/02/2021 12:16am | Delete |
| 3 | Customers | 20 | 11/02/2021 12:17am | Insert |However, database triggers are required for every table in the source database and have more overhead associated with running triggers on operating tables during a change.
Since trigger-based CDC works at the SQL level, many users prefer this approach.
Advantages of Trigger-based approach:
- very reliable and detailed.
- Shadow tables can provide an immutable, verbose log of all transactions.
A disadvantage of the Trigger-based approach:
- Reduces the performance of the database by requiring multiple writes to a database every time a row is inserted, updated, or deleted
DBAs and data engineers should always test the performance of any database triggers added into their environment and decide if they can tolerate the additional overhead.
Transaction Log CDC.
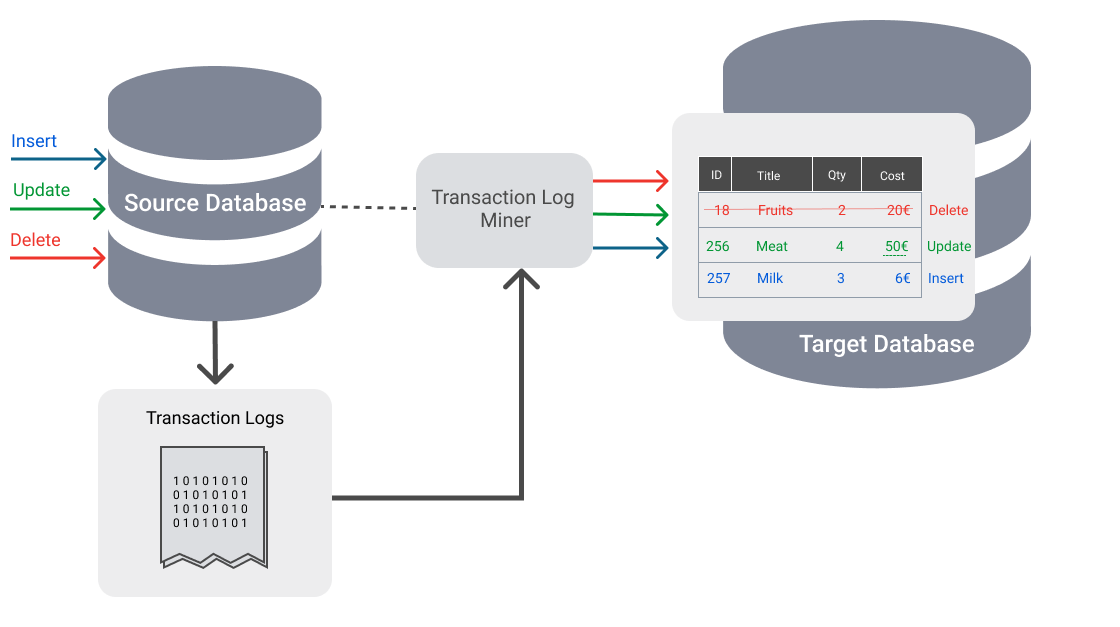
Databases use transaction logs primarily for backup and recovery purposes. But they can also be used to replicate changes to a target systems or a target data lake.
In a "transaction log" based CDC system, there is no persistent storage of data stream. Kafka can be used to capture and push changes to a target database.
The key difference between transaction log CDC and trigger-based CDC is that every change will go into a transaction log generated by the database engine.
A database engine uses native transaction logs (also called redo logs) to store all database events so that the database can be recovered in the event of a failure. There is no need to make any application-level changes or scan shadow tables.
Compared to Trigger-Based CDC, restoring data from transaction logs is somewhat tricky but possible.
Advantages of Transaction Log approach
- Minimal impact on production database system – no additional queries are required for each transaction.
- There is no need to change the schemas of the production database system or add additional tables.
Challenges of Transaction Log approach
- Parsing the internal logging format of a database is difficult - most databases do not document their transaction log format nor announce changes to it in new releases. This may require you to change your database log parsing logic with each new release of the database.
- Log files are often archived by the database engine. CDC software must read logs before they are archived by the database, or be able to read the archived logs.
- The additional log levels required to create scannable transaction logs can add minor performance overhead.
- The target database can accidentally become inaccessible when the CDC application is sending data. Unsent data must be buffered until the target database is brought back online. Failure to complete this step can result in data loss or duplicate data.
- Failure can occur if the connection to the source or target is lost, resulting in data loss, duplicate records or a restart from the initial data load.
"Trigger-based CDC" and "Transaction Log CDC" are database design patterns that you can use to build reactive distributed systems.
Trigger-based CDC uses its own events journal as the source of truth, while transaction log CDC relies on the underlying database transaction log as the source of truth.
Database triggers are used as part of every DB transaction to capture events as they occur immediately. For each insert, update, delete, a trigger is fired to record the changes. On the other hand, the transaction log CDC operates independently of transactions. It uses a redo log file to record changes. This improves performance as CDC operations are not tied directly to every transaction in your DB as they happen.
Why are we using a "Trigger-based" rather than a "Transaction Log-based" approach?
- It is often difficult to get customers to change their database settings to enable "Transaction Logs" on the host databases if they are disabled.
- Most databases do not document their transaction logs' format nor announce changes to it in new releases. This may require changing the logic for parsing the transaction log with each new release of the database.
- However, the trigger-based approach can degrade database performance because it requires multiple writes to the database. Every time an event occurs when a row is inserted, updated, or deleted. But for the "Transaction logs" approach, an additional log level is required to produce scannable transaction logs. It can add marginal performance overhead also.
Here is an Excerpt From the MySQL web page https://dev.mysql.com/doc/refman/8.0/en/binary-log.html
"Running a server with binary logging enabled makes performance slightly slower. However, the benefits of the binary log in enabling you to set up replication and for restore operations generally outweigh this minor performance decrement."
- The final decision was based on the fact that triggers are available for all modern databases.
So DBSync products and DBConvert Studio use "Trigger-based" database synchronization CDC method.
For clustered databases, this approach is arguably worse than using MySQL binlogs or PostgreSQL Transaction logs.
In any case, it would be interesting to compare the two approaches to determine the winner.
UPDATE: We've released our new event-driven real-time replication platform, DBConvert Streams. Benchmark test shows incredible results. Transferring 1 million records from source to destination takes about 12 seconds.
DBConvert Streams is a new data replication platform that uses CDC technology to stream data between databases.
Conclusion
CDC is an essential component of modern architectures for transferring transactional data from systems to the data stream.
CDC enables the provisioning of transactional data in real-time without causing a significant load to the source system, requires no changes in the source application, and reduces the transferred amount of data to a minimum.
CDC enables the provision of transactional data without causing significant load on the source system and reduces the amount of data transferred to a minimum.
The real benefits of using CDC are only realized with larger data sets. You'll see CDC a lot with enterprise data warehouses that emphasize analytics and historical data comparisons.