JSON Lines format: Why jsonl is what you need for data streams?
JSON Lines is appealing format for data streaming. Since every new line means a separate entry makes the JSON Lines formatted file streamable.
CSV and JSON formats introduction
Comma Separated Values (CSV) format is a common data exchange format used widely for representing sets of records with identical list of fields.
JavaScript Object Notation (JSON) nowadays became de-facto of data exchange format standard, replacing XML, that was a huge buzzword in the early 2000’s. It is not only self-describing, but also human readable.
Let’s look examples of both formats.
Here is a list of families represented as CSV data:
id,father,mother,children
1,Mark,Charlotte,1
2,John,Ann,3
3,Bob,Monika,2CSV looks a lot simpler than JSON array analog shown below:
[{"id":1,"father":"Mark","mother":"Charlotte","children":1},
{"id":2,"father":"John","mother":"Ann","children":3},
{"id":3,"father":"Bob","mother":"Monika","children":2}]But CSV is limited to store two-dimensional, untyped data. There is no any way to store nested structures or types of values like names of children in plain CSV.
[
{
"id":1,
"father":"Mark",
"mother":"Charlotte",
"children":[
"Tom"
]
},
{
"id":2,
"father":"John",
"mother":"Ann",
"children":[
"Jessika",
"Antony",
"Jack"
]
},
{
"id":3,
"father":"Bob",
"mother":"Monika",
"children":[
"Jerry",
"Karol"
]
}
]Representing nested structures in JSON files is easy, though.
JSON Lines vs. JSON
Exactly the same list of families expressed as a JSON Lines format looks like this:
{"id":1,"father":"Mark","mother":"Charlotte","children":["Tom"]}
{"id":2,"father":"John","mother":"Ann","children":["Jessika","Jack"]}
{"id":3,"father":"Bob","mother":"Monika","children":["Jerry","Karol"]}The JSON Line specification is very simple, there’s only a few rules to consider:
- UTF-8 encoding
- JSON Lines essentially consists of several lines where each individual line is a valid JSON object, separated by newline character
\n. - It doesn’t require custom parsers. Just read a line, parse as JSON, read a line, parse as JSON… and so on.
JSON lines specification and more details are available at https://jsonlines.org .
Actually it is already very common in industry to use jsonl
Why not just surround the whole data with a regular JSON array so the file itself is valid json?
In order to insert or read a record from a JSON array you have to parse the whole file, which is far from ideal.
Since every entry in JSON Lines is a valid JSON it can be parsed/unmarshaled as a standalone JSON document. For example, you can seek within it, split a 10gb file into smaller files without parsing the entire thing.
- No need to read the whole file in memory before parse.
- You can easily add further lines to the file by simply appending to the file. If the entire file was a JSON array then you would have to parse it, add the new line, and then convert back to JSON.
So it is not practical to keep a multi-gigabyte as a single JSON array. Taking into consideration that DBConvert users would require to stream big volumes of data we are going to support exporting to JSONL format.
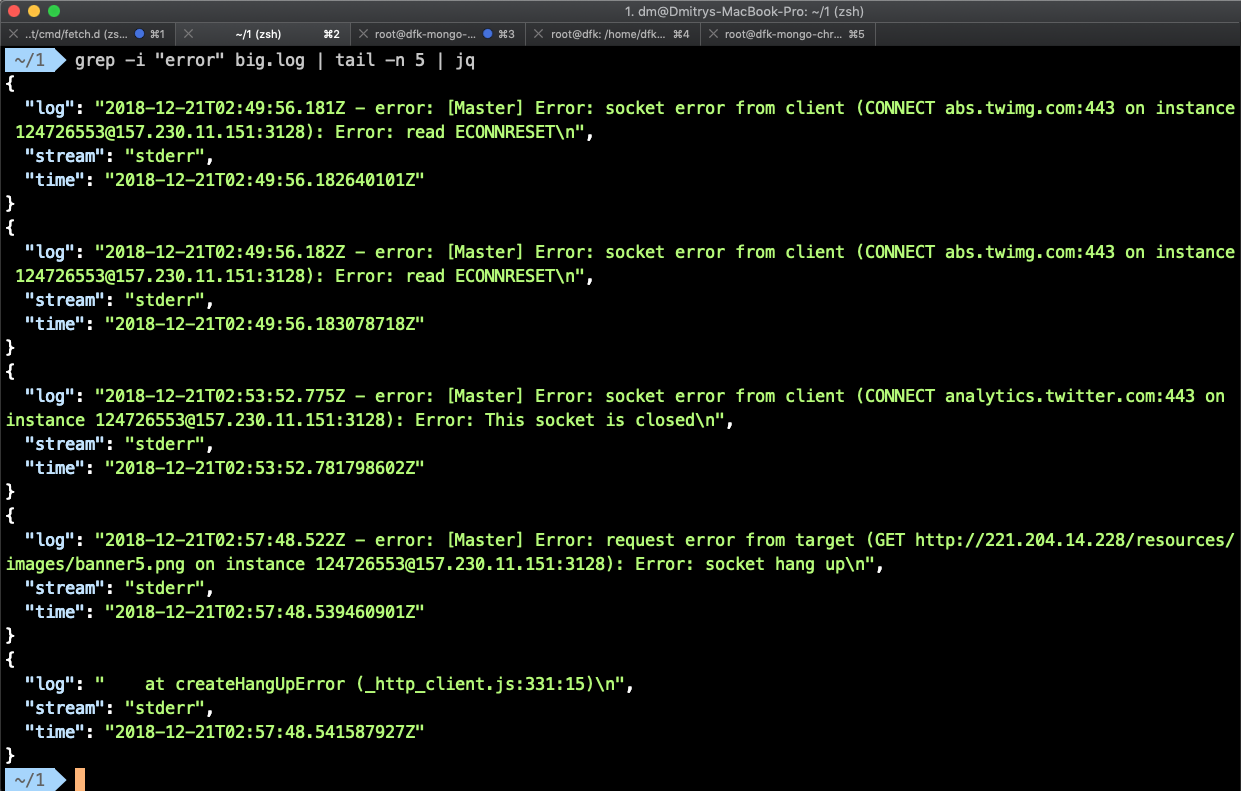
Let’s consider a real docker log file. It is actually JSON Lines formatted file which has a log extension though.
{"log":"2018-12-20T08:53:57.879Z - info: [Main] The selected providers are digitalocean/nyc1\n","stream":"stdout","time":"2018-12-20T08:53:57.889924185Z"}
{"log":"2018-12-20T08:53:58.037Z - debug: [Main] listen\n","stream":"stderr","time":"2018-12-20T08:53:58.038505968Z"}
{"log":"2018-12-21T02:57:48.522Z - error: [Master] Error: request error from target (GET http://21.24.14.28/resources/images/banner5.png on instance 124726553@157.230.11.151:3128): Error: socket hang up\n","stream":"stderr","time":"2018-12-21T02:57:48.539460901Z"}
...
{"log":"2018-12-21T02:57:53.021Z - debug: [Pinger] ping: hostname=142.93.199.42 / port=3128\n","stream":"stderr","time":"2018-12-21T02:57:53.339146838Z"}
{"log":"2018-12-21T02:57:53.122Z - debug: [Manager] checkInstances\n","stream":"stderr","time":"2018-12-21T02:57:53.339161183Z"}
{"log":"Killed\n","stream":"stderr","time":"2018-12-21T02:58:19.048581795Z"}The first 3 and last 3 lines are listed here for brevity. The size of the whole log file is about 30Mb and it is continuously growing.
$ wc -l docker.log
212496 docker.loglinux wc shows the log consists of 212496 lines
Using standard Linux command line tools like head and tail I can read first or last 3 lines accordingly.
$ head -n 3 docker.log
$ tail -n 3 docker.log
Running the command below you can periodically scrape out the last 5 errors from the log file every minute.
$ while true; do grep -i "error" docker.log | tail -n 5; sleep 60; doneHow many errors are there in the log file? It’s easy.
$ grep -i "error" docker.log | wc -l
45688In this casewctakes the output of thegrepcommand, which extracts lines containingerrorfrom the log file. You don’t ever worry about saving the grep results anywhere first. This is why piping of JSON lines files’ content, combined with a little shell scripting, makes such a powerful tool for data analysis.
Why can't we do all this with the usual JSON array?
- In particular case you should implement your custom parser to read/write a stream data.
- To keep a JSON array valid you have to always finish a file with trailing
]Right? What is the sign indicating there will be no upcoming data anymore? - Not every editor can load a really big regular JSON file without crashing or slowing down significantly.
- To make data fairly readable by humans just use
$ grep -i “error” docker.log | tail -n 5 | jqYou could choose to load output into a database and work with the data there. But is that the right choice? It might be overkill sometimes. What if you’re just examining the data to get a sense of what it contains? A lot of linux utils like grep, sed, sort, and etc. can manipulate \n divided records with ease.
The only little drawback of JSON Lines might be the fact that it is not a valid JSON anymore as a whole. But despite this drawback, processing of large volume data demonstrate a real advantage of jsonl.
JSON Lines use cases.
The first key point is to use JSON Lines for real-time data streaming like logs. Say, if you are streaming data over a socket (every line is a separate JSON and the most sockets have an API for reading lines).
Logstash and Docker store logs as JSON Lines.
One more case is using JSON Lines format for large JSON documents.
In one of our recent projects more than 2.5 Mln of URLs have been fetched and parsed. As a result we’ve got 11Gb or raw data.
In case of regular JSON there is really only the way to go — load all the data into memory and parse it. But you can seek particular position within JSON Lines, though, split a 11 GB file into smaller files without parsing the entire thing, use CLI \n based tools, etc.
JSON lines (jsonl), Newline-delimited JSON (ndjson), line-delimited JSON (ldjson) are three terms expressing the same formats primarily intended for JSON streaming.
Let’s look into what JSON Lines is, and how it compares to other JSON streaming formats.
JSON Lines vs. JSON text sequences
Let’s compare JSON text sequence format and associated media type “application/json-seq” with NDJSON. It consists of any number of JSON texts, all encoded in UTF-8, each prefixed by an ASCII Record Separator (0x1E), and each ending with an ASCII Line Feed character (0x0A).
Let’s look at the list of Persons mentioned above expressed as JSON-sequence file:
<RS>{"id":1,"father":"Mark","mother":"Charlotte","children":["Tom"]}<LF><RS>{"id":2,"father":"John","mother":"Ann","children":["Jessika","Jack"]}<LF>
<RS>{"id":3,"father":"Bob","mother":"Monika","children":["Jerry","Karol"]}<LF><RS> here is a placeholder for non-printable ASCII Record Separator (0x1E). <LF> represents the line feed character.
The format looks almost identical to JSON Lines excepting this special symbol at the beginning of each record.
As these two formats so similar you may wonder why they both exist?
JSON text sequences format is used for a streaming context. So this format does not define corresponding file extension. Though JSON text sequences format specification registers the new MIME media type application/json-seq. It is error-prone to store and edit this format in a text editor as the non-printable (0x1E) character may be garbled.
You may consider using JSON lines as an alternative consistently.
JSON Lines vs. Concatenated JSON
Another alternative to JSON Lines is concatenated JSON. In this format each JSON text is not separated from each other at all.
Here is concatenated JSON representation of an example above:
{"id":1,"father":"Mark","mother":"Charlotte","children":["Tom"]}{"id":2,"father":"John","mother":"Ann","children":["Jessika","Jack"]}{"id":3,"father":"Bob","mother":"Monika","children":["Jerry","Karol"]}Concatenated JSON isn’t a new format, it’s simply a name for streaming multiple JSON objects without any delimiters.
While generating JSON is not such a complex task, parsing this format actually requires significant effort. In fact, you should implement a context-aware parser that detects individual records and separates them from each other correctly.
Pretty printed JSON formats
If you have large nested structures then reading the JSON Lines text directly isn’t recommended. Use the jq tool to make viewing large structures easier:
grep . families.jsonl | jqAs a result you will see pretty printed JSON file:
{
"id": 1,
"father": "Mark",
"mother": "Charlotte",
"children": [
"Tom"
]
}
{
"id": 2,
"father": "John",
"mother": "Ann",
"children": [
"Jessika",
"Antony",
"Jack"
]
}
{
"id": 3,
"father": "Bob",
"mother": "Monika",
"children": [
"Jerry",
"Karol"
]
}How to convert JSON Lines to regular JSON
$ cat big.jsonl, | sed -e ':a' -e 'N' -e '$!ba' -e 's/\n/,/g' | sed 's/n/,/' | sed 's/^/[/'| sed 's/$/]/' > big.jsonThis command converts JSONL to JSON.
It takes about a second to convert 30 Mb file.
Conclusion
The complete JSON Lines file as a whole is technically no longer valid JSON, because it contains multiple JSON texts.
JSON Lines is appealing format for data streaming. Since every new line means a separate entry makes the JSON Lines formatted file streamable. You can read just as many lines as needed to get the same amount of records.
You don't have to invent custom reader/ writer to handle JSON Lines format. Even simple Linux command line tools likeheadandtailcan be used to read JSON Lines efficiently.