Data stream processing.
What is Data Stream processing? Collect, process and extract real value from data sources in real-time . Deliver data much faster than ever before.
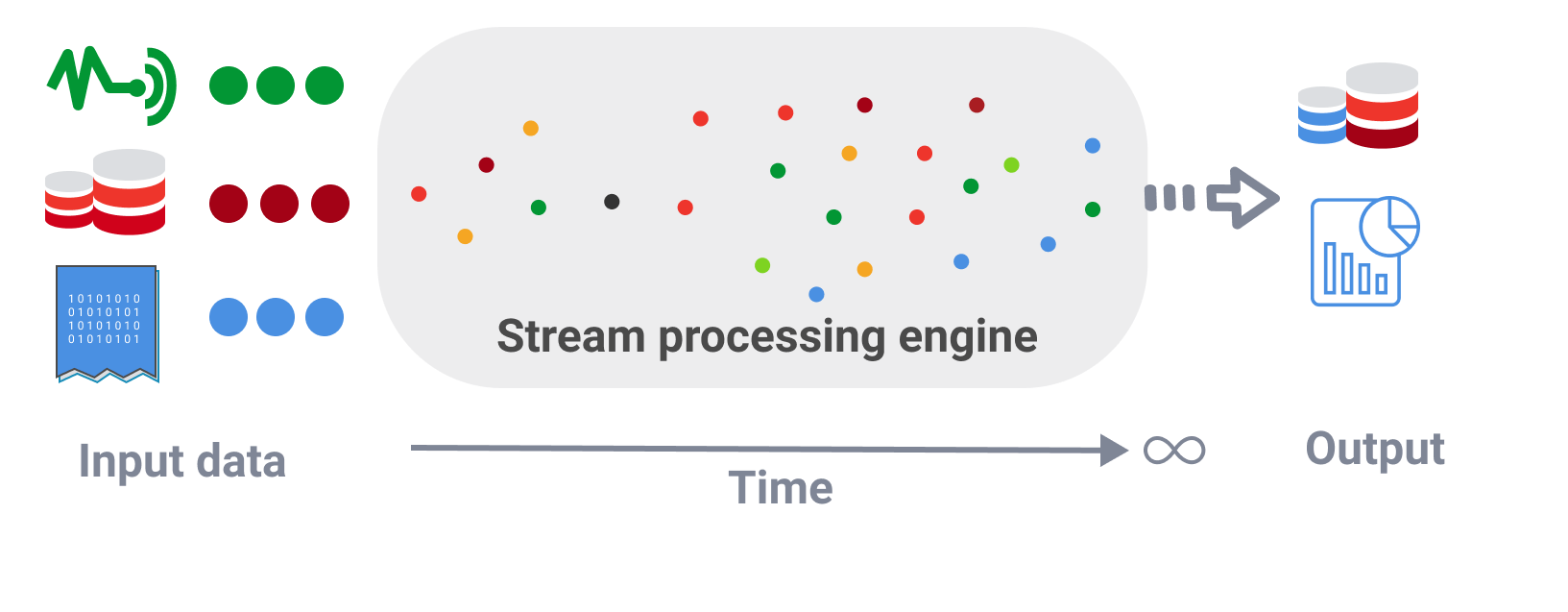
Today's data is generated from an infinite number of sources - IoT sensors, database servers, application logs. It is almost impossible to regulate the structure, data integrity, or control the amount or speed of data generated.
While traditional solutions are built to ingest, process, and structure data before it can be acted upon, streaming data architecture adds the ability to consume, persist to storage, enrich, and analyze data in motion.
As more and more data comes from a variety of event sources, there is a need for technology to collect, process data, and extract real value from data in real-time. Data should now be delivered much faster than ever before.
Sources for Streaming Data.
Streaming data is used in many industries. Strictly speaking, actually every data can be considered as streams. Some of the most popular use cases are listed below:
- IoT sensor Data. Industrial Machines, Consumer Electronics, Agriculture.
- Tracking users on websites. Online shops, Prices comparison portals.
- Monitoring. System health, Resource utilization, Traffic tracking systems.
- Automotive Industry. Vehicle tracking, Routing Information.
- Financial Transactions. Fraud Detection, Trade monitoring & Management.
Bounded data vs. Unbounded data.
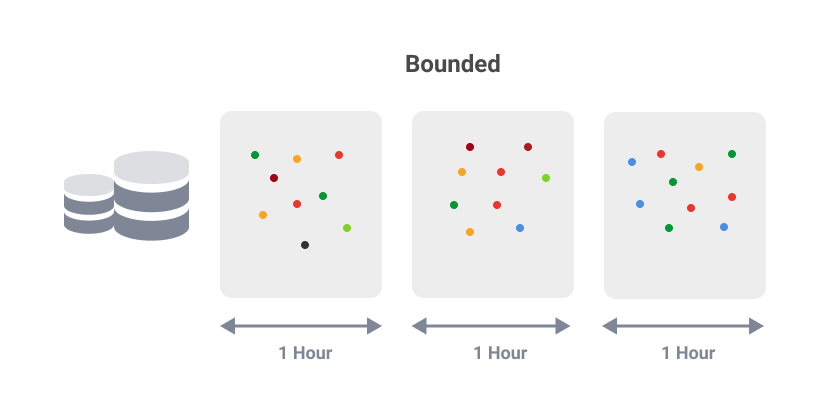
Bounded data is finite and has a discrete start and end. You can associate Bounded data with batch processing. For example, sales data for a company is collected daily. Then it is uploaded to the database every week, every month, or even every year. The analysis is run so that data insights are gained and outputs created through a batch process.
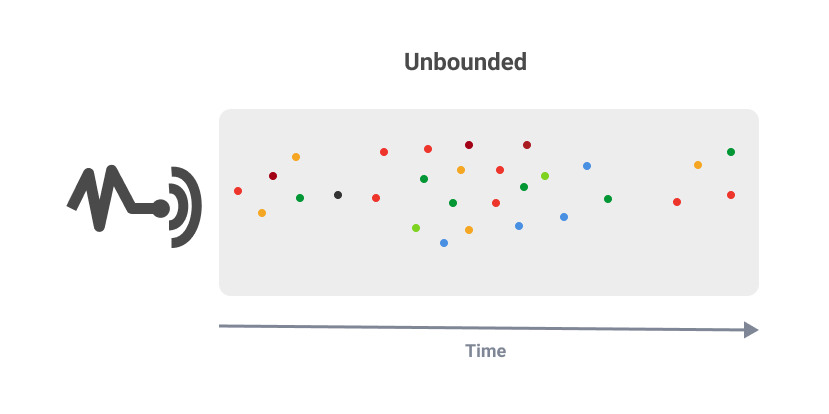
Unbounded data is infinite, having no discrete beginning or end. Unbounded data are typically associated with stream processing. As an example, sensors continually collect real-world data on temperature, speed, location, and more. Data collection never stops.This is a 24 hour continuous process.
We will discuss unbounded data and stream processing in this article.
What is stream processing?
Stream Processing combines the collection, integration, and analysis of unbounded data.
Stream processing delivers unbounded data continuously, rather than waiting for a batch job to complete at the end of a day or a week.
"Stream processing" and "batch processing" serve very different purposes. Batch Processing is excellent for analyzing trends, while Stream processing is great for analyzing and working on one event at a time.
Imagine that you are connecting to some data stream. Data arrives naturally as never ending streams of events. Thus, the processing is performed continuously, and you have no control over when the data arrives. It just happens when the data is being collected.
The data is coming in at high velocity. So usually, data analysis in Stream processing is much simpler than in batch processing systems because processing takes time and resources. The highest priority for Stream processing is to process the data as soon as possible.
Characteristics of Data Streams.
- Although a large amount of data can be ingested from event sources, the data records usually are small. This is some structured data in JSON, CSV, XML formats. Typically, the size of individual records does not exceed a couple of kilobytes. We're not talking about megabytes or gigabytes.
- Data volumes can be extremely high. You can expect a large number of messages arriving into the system that you need to handle.
- Uneven distribution of data. For example, you are tracking moving vehicles in a city. Chances are, you won't have a lot of load on the system at night because no one is driving. But in the morning, during rush hour, huge peaks await you.
- Data may arrive at the destination out of order compared to the time the event occurred. Typically, data is collected sequentially. But in the real world, when data travels through a network or Distributed Message Broker, it can end up in a consumer application processing data out of order compared to when the actual event occurred. Thus, the system must be designed to handle this correctly.
In many cases, as in the rush hour example above, the value of real-time data for decision-making diminishes over time.
For example, you are monitoring the traffic situation and want to see the cars passing by. The faster you can process this data, the more you can deploy this time-critical situation. You are trying to keep this road open to increase the number of passing cars. Over time, your ability to respond decreases. The ability to react and make urgent decisions depends on how quickly this data is collected.
Overview of Core Stream processing Workflows.
Filtering
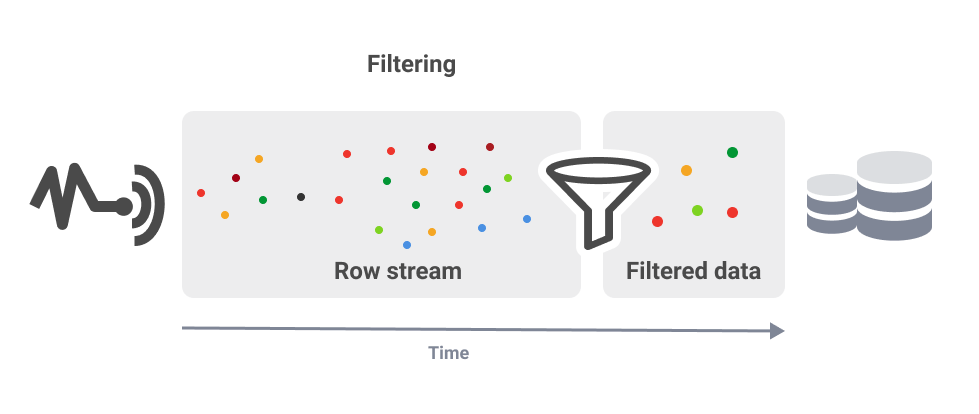
Reduce the amount of data in memory before saving it to disk.
Let's go back to our example about vehicle monitoring. Imagine how many cars arrive at a certain point on the road during rush hour. Keeping all these thousands of cars passing in a second is quite expensive. Perhaps you are just interested in a specific type of vehicle (SUV or truck). You can filter this data in a workflow and then commit it to disk. The other will filter by location. We may want to collect data from the whole country, but in reality, we are probably only interested in analyzing some specific areas.
Organizations are often interested in collecting datasets for only one scenario from the entire dataset, so filtering is vital.
Enrichment
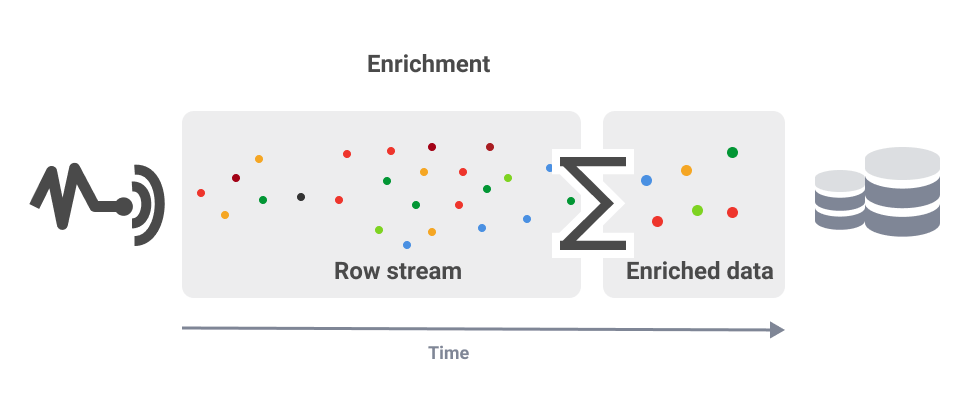
Data Enrichment is the joining of unbounded data and adding either first-party or third-party data to a dataset before storing them on a disk.
Why would you want to enrich your data in real-time rather than in your warehouse?
In the rush hour traffic example, if you enrich your data in real-time, you can make the right decision immediately during the event. Let's say you are enriching your data in a warehouse. In this case, you enrich it after the event, or you may even have to perform a complex location and time search to pinpoint what the situation was at the time, which is a much more expensive option.
When small chunks of data are streamed from sensors, there is no need to store all of that data to make intelligent decisions. In most cases, it is enough to have only the average value from several sensors for a certain time in the storage.
Aggregation
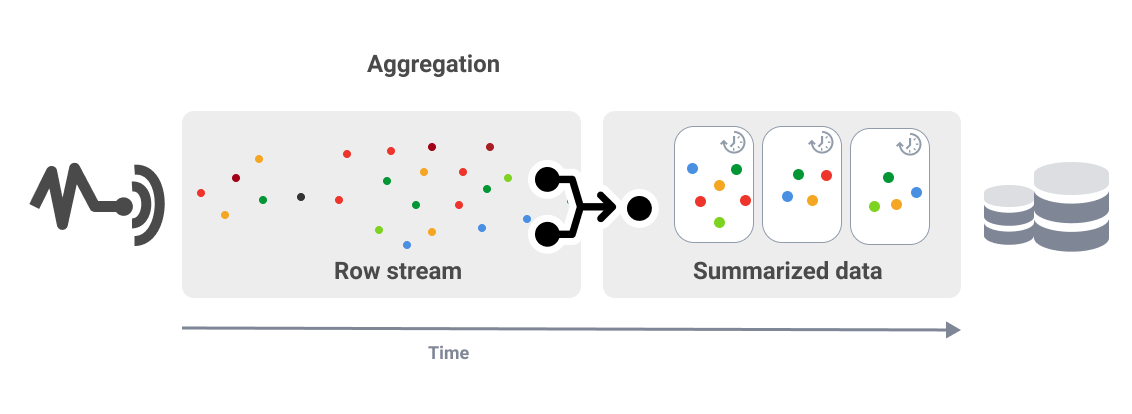
Aggregation is the summation of unbounded data by calculating aggregates within a time window before writing data to disk.
In this case, windowing is used for aggregation. To summarize data statistics for specific periods, you need to create beginning and ending points for each window for analysis.
For example, if you monitor air temperature with thousands of sensors in a province every minute, you probably don't need that level of detail. You can aggregate data over ten minutes for each windowed time frame.
Aggregation dramatically reduces the amount of data you need to store.
Why leverage cloud computing for Stream processing?
Technically it is possible to build on-premises infrastructure for streaming data processing. But it is much more cost-effective to leverage cloud services for stream processing tasks.
The scalability of clouds is phenomenal, so there is no need to focus on infrastructure, but you can focus directly on the problem.
A lot of sources of streaming data now are in the cloud. It is a great time now that the data collection and "stream processing" related services like Data Lakes, Data Warehouses, IoT Devices are just exploding with 5G coming online.